Posts tagged "emacs":
AI assistants in Emacs. Don't use ChatGPT. Help Open Science.
Everybody seems to be very excited about generative AI models these days. The availability of the Large Language Models (LLMs) through conversational interfaces like ChatGPT and of image generation tools like Dall-E or Stable Diffusion have brought generative AI to the masses. Although Github Copilot, also based on the GPT family of models, has been available for a while now, this was a niche tool, for programmers only.
Of course, Emacs being the best text-based interface to a computer, it is also the best interface to the generative AI models which are driven through textual prompts. Everything being a text buffer in Emacs, sending and receiving text via an API is straightforward (if you know Emacs Lisp).
It is therefore not a surprise that there are many Emacs packages allowing to use ChatGPT and Copilot. Just to list a few1:
Recently, David Wilson at System Crafters did a live stream showing some of the capabilities of these packages. To be honest, I was not impressed by the results of the code generated by the LLMs, but I can understand that many people may find them useful.
At the end of the stream, David wanted to address the question of the problems and issues with using these models. Of course, being a programmer, David likes recursion, and he asked ChatGPT about that. The LLM answered, as usual, with a balanced view with pros and cons. It is also usual for these models, in my opinion, to give awfully banal answers. There can be legal issues, copyright ones (in both senses, that is, that the models are trained with copyrighted material, and that the copyright of their outputs is not well defined), ethical problems, etc.
As always, the Silicon Valley tech firms have not waited for these issues to be settled before deploying the technology to the public. They impose their vision regardless of the consequences. Unfortunately, most programmers like the tech so much that they don't stop thinking before adopting and participating in spreading it.
Emacs being one of the most important contributions of the Free Software community, it may be surprising that some of its users are so keen to ride the latest Trojan horse of technofeudalism. Fermin pointed out a similar kind of issue with the Language Server Protocol, but that was not a real problem, since LSP servers run locally and we have free software implementations of them. This is not the case for ChatGPT or Copilot. We only have an API that can be taken down at any moment. But worse than that, as pointed out, using these LLMs means that we are working in training them. Every time that David, in his demo, wrote "… the code is wrong because of …, can you fix it?", he was giving feedback for the reinforcement learning of ChatGPT.
So what can we do? Stop using these tools and loose our programming or writing jobs because we will be less productive than those that use them?
Maybe we can do what GNU hackers and other Free Software activists have always done: implement libre tools that are digital common goods that free and empower users. Building and training big AI models is very costly and may be much more difficult than building an OS kernel like Linux, GCC or Emacs, but fortunately, there are already alternatives to ChatGPT.
The best starting point could be helping the BigScience Project by using their Bloom model from Emacs to train it and improve it. Hints on how to install Bloom locally and use it with Python can be found in this blog post. There are also initiatives to use federated learning2 to improve Bloom. The BigCode project targets code generation, and is to BigScience what Copilot is to ChatGPT. You can play with it here. There is a VSCode plugin for their StarCoder model, but no Emacs package yet. Isn't that a shame?
BigScience is Open Science, while OpenAI's is not open, but proprietary technology built from common digital goods harvested on the internet. It shouldn’t be difficult for us, Emacs users, to choose who we want to help.
A workaround for an annoying EXWM behavior
I have been using the Emacs X Window Manager, EXWM, for a couple of years now and I have come to depend on it for an efficient and friendly workflow for most of what I do at the computer. Before that, I had been using StumpWM for 4 or 5 years and I was already sold on tiling window managers. For someone like me who does everything in Emacs except for browsing sites that need Javascript or watching videos, EXWM seems to be the perfect setup.
The pain point with EXWM is that its development and maintenance suddenly stopped after the creator and maintainer went AWOL. There have been discussions here and there to continue the development, but, to the best of my knowledge, no initiative has really taken off.
Some well known EXWM users in the community started migrating to other WMs, like StumpWM, Herbstluftwm or or QTile. I also tried to get back to StumpWM, since I had used it for a long time, but I found the experience inferior to EXWM: having M-x everywhere and not having to use different key bindings when talking to the WM or to Emacs is a real comfort.
However, some time ago, floating windows started behaving annoyingly. For instance, when saving a file in Firefox, the file chooser application would be too high and the Save button would be below the bottom of the screen. I then would have to move the window up so that I could click. Not knowing anything about X, I wasn't able to diagnose the issue.
I ended writing a little function to resize a floating window:
(defun my/resize-floating-frame (width height) "Resize a floating exwm frame to WIDTHxHEIGHT" (interactive "nWidth: \nnHeight: ") (let ((floating-container (frame-parameter exwm--floating-frame 'exwm-container))) (exwm--set-geometry floating-container nil nil width height) (exwm--set-geometry exwm--id nil nil width height) (xcb:flush exwm--connection)))
and bound it to a key to call it with a size that would fit:
(exwm-input-set-key (kbd "s-x r") (lambda () (interactive) (my/resize-floating-frame 600 800)))
So now, instead of grabbing the mouse and manually moving the window, I could just use s-x r and hit enter, since the Save button is selected by default. This is a big win, but after a couple of days, I became tired of this and thought that this could be automated. Also, the arbitrary fixed size may not be appropriate depending on the monitor I am using.
So with a little more elisp, I wrote a function that computes the size of the window and works with a hook which is called by EXWM and the end of the setup of the floating window:
(defun my/adjust-floating-frame-size () "Ensure that the current floating exwm frame does not exceed the size of the screen" (let* ((frame (selected-frame)) (width (frame-pixel-width frame)) (height (frame-pixel-height frame)) (w1 (elt (elt exwm-workspace--workareas 0) 2)) (h1 (elt (elt exwm-workspace--workareas 0) 3)) (w2 (elt (elt exwm-workspace--workareas 1) 2)) (h2 (elt (elt exwm-workspace--workareas 1) 3)) (max-width (round (* 0.75 (min w1 w2)))) (max-height (round (* 0.75 (min h1 h2)))) (final-height (min height max-height)) (final-width (min width max-width))) (set-frame-size frame final-width final-height t))) (add-hook 'exwm-floating-setup-hook #'my/adjust-floating-frame-size 100)
All this may seem complex and one could think that too much elisp-foo is needed to do all this. This is absolutely not the case. With a little effort and time, it is not difficult to navigate the source code and test things interactively to see how they behave. In this particular case, searching for hooks in the EXWM package (M-x describe-variable) and trying little code snippets on the *scratch* buffer got me there rather quickly.
This is yet another demonstration of the power of Emacs: you can modify its behavior interactively and all source code and documentation is immediately accessible. You don't need to be a skilled programmer to do that.
That's user freedom, the real meaning of software freedom.
Read e-books from your Calibre library inside Emacs
I read many books in electronic format. I manage my e-book library with the great Calibre software. For non fiction books (science, philosophy, productivity, computer science, etc.) I like to read on my laptop, so I can easily take notes, or actually generate Zettels. Since I create new zettels with org-capture, reading inside Emacs is very handy. For EPUB format, I use the excellent nov.el and for PDF files I use pdf-tools. Both of these packages provide org links, so I don't have to do anything special to capture notes and have a back-link to the point in the e-book where the note was taken from. This is standard org-capture.
I also use org links as bookmarks between reading sessions. Yes, that is bookmarks as marks in the book, like real, paper books.
The part in my reading workflow where Emacs wasn't used was managing the e-book library. Usually, when I got a new book, I would open Calibre, add the book, fetch missing meta-data and cover if needed and then close Calibre. After that, I would use calibre-mode.el to call calibre-find to search for the book and insert an org link into my reading list.
I have been aware of calibredb.el for a couple of years (or maybe a little less), but I had not used it very much. After a recent update of my packages, I had a look at it again and I discovered that it provides all the features I use in the Calibre GUI, so I have started to use it to add books and curate meta-data and covers.
calibredb has a function to open a book from the list: calibredb-open-file-with-default-tool which in my case runs ebook-viewer for EPUB and evince for PDF. I did not find an option or a variable to change that, so I looked at the code of the function:
(defun calibredb-open-file-with-default-tool (arg &optional candidate) "Open file with the system default tool. If the universal prefix ARG is used, ignore `calibredb-preferred-format'. Optional argument CANDIDATE is the selected item." (interactive "P") (unless candidate (setq candidate (car (calibredb-find-candidate-at-point)))) (if arg (let ((calibredb-preferred-format nil)) (calibredb-open-with-default-tool (calibredb-get-file-path candidate t))) (calibredb-open-with-default-tool (calibredb-get-file-path candidate t))))
This function calls calibredb-open-with-default-tool, which looks like this:
(defun calibredb-open-with-default-tool (filepath) "TODO: consolidate default-opener with dispatcher. Argument FILEPATH is the file path." (cond ((eq system-type 'gnu/linux) (call-process "xdg-open" nil 0 nil (expand-file-name filepath))) ((eq system-type 'windows-nt) (start-process "shell-process" "*Messages*" "cmd.exe" "/c" (expand-file-name filepath))) ((eq system-type 'darwin) (start-process "shell-process" "*Messages*" "open" (expand-file-name filepath))) (t (message "unknown system!?"))))
So in GNU/Linux, it calls xdg-open, which delegates to the appropriate applications. But of course, I want to use Emacs.
I could use xdg-settings to change the behavior, but that would mean using emacsclient which seems weird given that I am already inside Emacs (actually, I use EXWM, so it is still weirder). Furthermore, since my Emacs is configured to open EPUB files with nov.el and PDF with pdf-view, I only need to call find-file on the selected file.
So I just adapted calibredb-open-file-with-default-tool and bound it to the same key as the original function:
(defun my/calibredb-open-file-with-emacs (&optional candidate) "Open file with Emacs. Optional argument CANDIDATE is the selected item." (interactive "P") (unless candidate (setq candidate (car (calibredb-find-candidate-at-point)))) (find-file (calibredb-get-file-path candidate t))) (define-key calibredb-search-mode-map "V" #'my/calibredb-open-file-with-emacs)
This is yet another demonstration of the power of Emacs: packages that were not designed to work together can be combined exactly as you want. You don't need to be a skilled programmer to do that.
That's user freedom, the real meaning of software freedom.
Install Emacs with Conda
At work, I frequently use a high performance computing cluster (300 nodes, 1000 CPU, 44 TB of RAM). It is an amazing environment. Many users access the system via Jupyter Hub and Virtual Research Environments where many tools for development are available. However the recommended editor is VSCode and I need Emacs.
I access the system via ssh on a terminal and run Emacs without the GUI. This is enough for me, since I have all I need:
- Window multiplexing using Emacs windows
- Virtual desktops thanks to tab-bar-mode
- Persistence across sessions using
desktop-save-mode - IDE features with eglot
- A data science environment with org-mode's babel
This is great, since I can use the same tools I use on my laptop, with the same configuration and be really efficient.
Unfortunately, a couple of months ago, the web proxy that we have to go through to access the internet from the cluster was upgraded and the old Emacs version available on the system was not able to fetch packages.
Doing some research, I found that Emacs 27 could be configured to work. Since I did not want to bother the sysadmins without being sure that it would work, I decided to compile Emacs from source as I do on my laptop.
Unfortunately, I couldn't manage to get all dependencies working. So I needed to find another way to have a recent Emacs on the system.
On the cluster, we use Conda to build virtual environments for scientific computing. With Conda, we can install whatever package we want at the user level without any particular privilege.
So I just did:
conda install emacs
and I got the last stable Emacs release, which is 27.2 at the time of this writing.
So if you need to use Emacs in a system where you can't install system wide packages and you don't want or can't build it yourself, Conda can be a good solution. Installing Conda does not need particular privileges.
Some Org Mode agenda views for my GTD weekly review
GTD Weekly review
What's GTD
I am an extremely lazy and messy person. As such, in order to survive, I need a system to find my way out of bed in the morning, have something to eat in the fridge, don't forget to pick my children at school, feed the cat and things like that.
More than 15 years ago, when I already was an Emacs user, I heard about Getting Things Done (GTD for short), a book and a personal productivity system that promised to save my life. I bought the book and started implementing the system right away. If you don't know anything about GTD, reading the Wikipedia entry will give you a good overview. In short, the action management part of the system relies on the following steps:
- Capture everything you have to remember or solve.
- Periodically empty your inboxes (what you have captured, and any other input you get as e-mail, physical stuff, etc.).
- Transform every input into either actionable things, reference material or trash. Actionable things can be projects (need more than one action), next actions (everything is ready to do what you need to do) or things to delegate.
- Maintain lists for actions and projects.
- Periodically review your lists.
- Don't forget to do some of your actions from time to time!
This is a crude description of the system, but it will be enough for the rest of this article.
The funny thing is that one could imagine that, as an avid Emacs user, I looked for ways to implement GTD with it. But the real story is that I discovered GTD because, when I was looking for ways to manage actions with Emacs I found what I think is the absolute reference on the use of Org Mode to get organized, and GTD is cited there.
Implementing GTD with org-mode
My implementation is much inspired by Bernt Hansen's suggestions in the above-mentioned site. For actions, I use the following states:
(setq org-todo-keywords (quote ((sequence "TODO(t!/!)" "NEXT(n!/!)" "STARTED(s!)" "|" "DONE(d!/!)") (type "PROJECT(p!/!)" "|" "DONE_PROJECT(D!/!)") (sequence "WAITING(w@/!)" "SOMEDAY(S!)" "|" "CANCELLED(c@/!)"))))
The meaning of these states is:
- NEXT
- an action that I need to do, for which I have estimated the effort, and for which I have everything to start acting.
- TODO
- an action that I need to do but that I don't want to see in my next actions list.
- STARTED
- a next action for which some progress has been made.
- DONE
- a finished action.
- WAITING
- an action to be done, but for which I am waiting for some input or some action from somebody else.
- SOMEDAY
- an action that could be interesting to do, but on which I don't want to commit yet.
- CANCELLED
- an action that I decided that I finally don't need to do.
The projects are just containers for related actions.
Next actions are very important. They are what allows to achieve progress even in periods of crisis or low energy. All my actions have tags for contexts. These can be general (work, admin, errands) or specific (the name of a particular project or person, a type of activity (reading, programming, writing). This allows to easily generate lists of actions which match a set of tags. The final thing that makes a next action special is the effort estimation. Using Org Mode properties, I assign an effort estimation to each next action, so that I can also filter by estimated duration when I have limited time available.
Since I spend most of my time in Emacs, using the Org Agenda makes being organised an easy and pleasant experience. The Org Agenda is my main dashboard that I trigger with C-c a. I think this is the default key binding, but I have this in my Emacs config:
(define-key global-map "\C-ca" 'org-agenda)
My Org Agenda is built from more than 60 Org Mode files.
The GTD weekly review
One key part of maintaining a clean GTD system is the weekly review. Once a week, I sit down for 90 minutes to 2 hours and I go through this checklist:
[ ]Re-schedule / re-deadline today's tasks[ ]Collect loose papers and materials[ ]Mental collection[ ]Get ins to zero- Questions :
- What is it?
- Actionable?
- Yes
- Next action?
- 2minutes? (do it)
- delegate? (waiting for)
- defer it to a specific date?
- or next action to do it ASAP (tag next)
- Is it multiple actions?
- Project
- Next action?
- No
- Reference material (tag reference)
- Incubate (remind me later) (tag incubate)
- Trash it
- No
- Yes
- Actionable?
- What is it?
- Questions :
[ ]Get current[ ]Review next actions list[ ]what might have been important may not be it anymore[ ]check that we have effort for all
[ ]Go back to previous calendar data[ ]things which got rescheduled or should[ ]actions which were not done
[ ]Review upcoming calendar[ ]Review waiting for list[ ]Stuck projects[ ]Look at project list[ ]Review relevant checklists
[ ]Get creative[ ]review someday/maybe[ ]generate new ideas
For some of these steps, I have Org Agenda custom commands or specific agenda views which are very useful. I am sharing them below.
Reschedule / redeadline today's tasks
After a week without reviewing my system, undone actions begin to pile-up and my dashboard is very crowded. The first step is therefore reschedule or cancel some actions. For that, I generate a Daily Action List with the following Org Agenda custom command:
(setq org-agenda-custom-commands (quote (("D" "Daily Action List" ((agenda "" ((org-agenda-span 1) (org-agenda-sorting-strategy (quote ((agenda time-up category-up tag-up)))) (org-deadline-warning-days 7)))) nil) ;; [....] )))
With C-c a D, I get all the actions for the current day and all undone things which were scheduled earlier or for which the deadline has passed, will also appear. The actions with a deadline in the coming 7 days will also show up.
Get current
The first step in getting current, is looking at the list of all next actions. For this, I have a group of custom commands. There is one for all actions, and 2 others which select only work or only home actions respectively:
Review next actions list
(setq org-agenda-custom-commands (quote ( ;; [....] ("n" . "Next Actions List") ("nn" tags "+TODO=\"NEXT\"|+TODO=\"STARTED\"") ("na" tags "+home+admin+TODO=\"NEXT\"|+home+admin+TODO=\"STARTED\"") ("nh" tags "+home+TODO=\"NEXT\"|+home+TODO=\"STARTED\"") ;; [....] )))
I can see all my next actions (with TODO state being NEXT or STARTED) by typing C-c a n n.
Check that we have effort for all
As I said above, I want to have an effort estimate for all my next actions. I use org-ql to generate an agenda view with all next actions that don't have Effort property. I display that with the following interactive command:
(defun my/show-next-without-effort () (interactive) (org-ql-search (org-agenda-files) '(and (todo "NEXT") (not (property "Effort")))))
Go back to previous calendar data and Review upcoming calendar
One crucial exercise in the weekly review is to have a look at the past week and the coming ones so that we see what we have done, what we should have done but didn't, and what's coming ahead.
For this, I also generate an agenda view with 24 days, starting 10 days ago. This way I see the last week and a half and the next 2 weeks. I have built the following interactive command to do that:
(defun my/generate-agenda-weekly-review () "Generate the agenda for the weekly review" (interactive) (let ((span-days 24) (offset-past-days 10)) (message "Generating agenda for %s days starting %s days ago" span-days offset-past-days) (org-agenda-list nil (- (time-to-days (date-to-time (current-time-string))) offset-past-days) span-days) (org-agenda-log-mode) (goto-char (point-min))))
Putting the agenda in log mode, allows to see the tasks marked as DONE at the corresponding time of closing. If, like me, you clock all your working time, the task will appear also every time it was worked on. This is great to get a sens of what was accomplished.
Review waiting for list
Reviewing all the actions that are blocked because they are delegated or need an input from someone else is important. Org Mode allows to generate an agenda view for that with the standard agenda dispatcher. Typing C-c a T generates an agenda view with all tasks matching a particular TODO keyword. I enter WAITING at the prompt and that's all!
Stuck projects
Sometimes, a project (that is, something that needs several actions to be done) gets stuck. Org Mode has a concept of stuck project (see the description of the variable org-stuck-projects), but I found it difficult to configure to my liking. I use org-ql again to generate a custom command like this:
(setq org-agenda-custom-commands (quote ( ;; [....] ("P" "Stuck Projects" ((org-ql-block '(and (todo "PROJECT") (or (not (descendants)) (and (not (descendants (or (todo "STARTED") (todo "NEXT")))) (descendants (and (or (todo "TODO") (todo "WAITING")) (not (deadline)) (not (scheduled))))) (not (descendants (or (todo "NEXT") (todo "TODO") (todo "WAITING") (todo "STARTED"))))))))) ;; [...] )))
For me, a stuck project is a headline with a PROJECT keyword that does not have a next action, or for which the non next actions don't have a deadline or a scheduled time slot.
Look at project list
To generate the list of projects, I use the same approach as for the list of next actions.
(setq org-agenda-custom-commands (quote ( ;; [....] ("p" . "Projects List") ("pp" tags "+TODO=\"PROJECT\"") ("pw" tags "+TODO=\"PROJECT\"+work") ("ph" tags "+TODO=\"PROJECT\"+home") )))
Typing C-c a p p gives me the list of all my projects.
Review someday/maybe
Having a list of things you may want to do someday is exciting. You can add whatever you want knowing that you don't have to commit to it unless or until you feel like it. However, sometimes you forget for too long about all those things and reviewing them can give new ideas or put you in the mood to commit.
The main problem with a someday/maybe list is that it keeps growing, so you can't review it weekly. Mine contains more than 2650 items! What I do is that I randomly jump to one point in the list and review items for 5 minutes. I use the following interactive command:
(defun my/search-random-someday () "Search all agenda files for SOMEDAY and jump to a random item" (interactive) (let* ((todos '("SOMEDAY")) (searches (mapcar (lambda (x) (format "+TODO=\"%s\"" x)) todos)) (joint-search (string-join searches "|") ) (org-agenda-custom-commands '(("g" tags joint-search)))) (org-agenda nil "g") (let ((nlines (count-lines (point-min) (point-max)))) (goto-line (random nlines)))))
It seems a little convoluted, since I could have done the same thing as for the waiting for list, but with this command I can use other TODO states by adding them to the list in the first line of the let. Also, the jump to a random point is cool.
Conclusion
As you can see, I have a custom set of commands and functions to make my weekly review easy. This is important. Until I automated this things, I would tend do skip the review too often. Now that I have a streamlined workflow I am much more disciplined with my weekly reviews and this results in an increased peace of mind.
My elisp code may need cleaning and improvements. Do no hesitate to send me some feedback by e-mail if you have any suggestion or tricks to share.
My Zettelkustom (with Emacs, of course)
Zettelwhat?
A couple of years ago, I was trying to improve my note taking abilities and did some research. I discovered the Zettelkasten method and read the book How to take smart notes by Sönke Ahrens which describes this approach invented by Niklas Luhmann, a German sociologist.
For a quick introduction to the method, I find this web site very well done. If you get interested in Zettelkasten, before jumping to the last shiny app or Emacs package, I think it's better to read Ahrens' book.
Anyway, in a few words, in Zettelkasten, you create notes with small bits of knowledge that are meant to be self contained. These notes may contain links to other notes with related content. The idea is that the knowledge is not organized hierarchically, but in a graph where notes point to other notes.
The Zettelkasten is a living thing where notes are regularly added and most importantly, the notes are frequently read and improved, either by reformulating the content, adding links to other notes, etc.
The Zettelkasten is meant to be personal, edited by a single person. It's like a second brain.
Niklas Luhmann did everything by hand and his Zettelkasten was made of paper cards. He had to invent a clever indexing method and used special structure notes to create tables of contents for different subjects. It is a pleasure to browse the original Zettels.
In order to implement a digital Zettelkasten, we only need a note taking application with the ability to create links between notes. A nice bonus is adding tags to the notes to simplify search and generation of sets of related notes.
There are lots of applications on the proprietary software market that support the creation and management of a Zettelkasten. There are also free software counterparts.
Emacs offers several alternatives in terms of packages:
- Neuron mode, which uses markdown;
- org-zettelkasten, which is a set of functions on top of org-mode;
- Zetteldeft, which uses deft;
- org-roam, based on org-mode and inspired by a commercial application.
There are probably others that I am not aware of. Org-roam seems to be the most popular one.
After reading Ahrens' book, I decided that I wanted to try the approach. I did not think want to choose one of the available Emacs packages for several reasons. The first one is that I did not understand why I needed anything else than plain org-mode. The second one was that I did not want to commit to any particular implementation before understanding how and if the approach would be useful for me.
How I do Zettelkasten
I have a big org-mode file called zettels.org with to top-level headings, one for structure notes and another one for standard zettels. Each note is a second level heading with a title, possibly some org-mode tags, a property drawer and the note content.
The property drawer contains at least the DATE_CREATED property with an inactive org-mode timestamp for the day and time when the note was created.
The structure notes are created by hand. That means that I create a heading, write the note and add the DATE_CREATED property. I do not create many structure notes, so a manual workflow is OK.
For the standard zettels, I use org-capture. The capture template automatically inserts the DATE_CREATED property, but also a FROM property with an org-mode link to the place I was in Emacs when I run org-capture. This link can therefore point to another Zettel (for which an org-id will be created), any org-mode heading if I am in an org-mode file, but this can also be an e-mail in Gnus, a pdf document, an EPUB file, a web page, etc. This is possible because I do everything in Emacs. Storing where I was when I created the note gives interesting context.
I have 2 org-capture templates for Zettelkasten, one which does what I described above, and another one which is used for quotes. The latter will copy the marked region in the current buffer into a quote org-mode block.
So a typical captured zettel may look like this:
** The title of the note :tag1:tag2: :PROPERTIES: :DATE_CREATED: [2021-08-06 Fri 22:43] :FROM: [[nov:/home/garjola/Calibre Library/abook.epub::26:7069][EPUB file at /home/garjola/Calibre Library/abook.epub]] :END: My ideas on the subject. Etc. #+begin_quote Some text that was marked in the EPUB I was reading. #+end_quote - See also [[id:e2b5839d-d7ef-4151-8676-17dacd261e86][Another note linked with org-id.]]
This way, while I am reading interesting things, I can capture an idea with all its context. I will of course come later to this note to improve it.
This is done in my regular gardening sessions. During these sessions, I browse the Zettelkasten, read notes, add tags and links to other notes, rewrite things, etc.
For this tasks, I use a couple of functions. The first one jumps to a random Zettel, so I am sure that I regularly explore forgotten parts of the Zettelkasten. The second one finds back-links, that is notes having links that point to the current note. This is useful for a bi-directional browsing of the content.
My custom Zettelkasten setup
Capture templates for Zettelkasten
The first component of the setup is the capture templates. They look like this:
(setq org-capture-templates (append org-capture-templates (quote (("z" "Zettelkasten") ("zz" "Zettel" entry (file+headline "~/org/zettels.org" "Zettels") (function my/zettel-template) :empty-lines 1) ("zq" "Quote" entry (file+headline "~/org/zettels.org" "Zettels") (function my/zettel-quote-template) :empty-lines 1)))))
There are 2 templates, one for notes without quotes (called with zz) and another for notes where I want to insert the marked region in the current buffer as a quote (called with zq). Both templates insert the note in the zettels.org file under the Zettels heading. Instead of writing the template in this code, I prefer using a function to generate it. I find this more readable.
The 2 functions are here:
(defun my/zettel-template () "* %?\n:PROPERTIES:\n:DATE_CREATED: %U\n:FROM: %a\n:END:\n%i\n") (defun my/zettel-quote-template () "* %?\n:PROPERTIES:\n:DATE_CREATED: %U\n:FROM: %a\n:END:\n#+begin_quote\n%i\n#+end_quote")
They are straightforward. The cursor is placed in the heading (with the %? org-expansion) so I can write the title. The property drawer will contain the time stamp and a link to the place Emacs was when org-capture was called. In the case of the quote, the marked region is copied inside the org-mode quote block.
And that's it!
Back-links to zettels
Back-links can be tricky. The package org-sidebar provides a function for that. But for some reason that I don't remember, I didn't like the way it worked (or more probably, my incompetence did not allow me to make it work). So I searched a bit and found a bit of elisp that does what I need.
(require 'org-ql) (require 'org-ql-view) (defun my/zettel-backlinks () (interactive) (let* ((id (org-entry-get (point) "ID")) (custom-id (org-entry-get (point) "CUSTOM_ID")) (query (cond ((and id custom-id) ;; This will be slow because it isn't optimized to a single regexp. :( (warn "Entry has both ID and CUSTOM_ID set; query will be slow") `(or (link :target ,(concat "id:" id)) (link :target ,(concat "id:" custom-id)))) ((or id custom-id) `(link :target ,(concat "id:" (or id custom-id)))) (t (error "Entry has no ID nor CUSTOM_ID property")))) (title (concat "Links to: " (org-get-heading t t))) (org-agenda-tag-filter nil)) (org-ql-search (quote ("~/org/zettels.org")) query :title title)))
It uses the wonderful org-ql package to search all org headings with a link matching the org-id of the current note. The search is limited to my zettels.org file.
Jump to a random zettel
The last bit I needed for serendipity is jumping to a random note. For this, I use the org-randomnote package. This package uses the org-randomnote-candidates variable to store the list of files that will be searched for random headings. It is initialized to the value of org-agenda-files. I just wrote a couple of functions to temporary change the list of candidate files so that I can limit the random jump to my zettels file:
(defun my/random-note (candidates) "Jump to a random org heading in one of the `CANDIDATES` files" (let ((old-randomnote-candidates org-randomnote-candidates)) (setq org-randomnote-candidates candidates) (org-randomnote "zettels") (setq org-randomnote-candidates old-randomnote-candidates))) (defun my/random-zettel () "Jump to a random zettel" (interactive) (my/random-note '("~/org/zettels.org")))
Moving to org-roam (or maybe not)
My first Zettel dates back to December 30 2019. I've been using this system since then and I am very happy with it. A year ago, I started seeing a big buzz about org-roam and I looked into it. It seemed very nice, with functionalities that I don't have in my system and I started wondering whether I should use it. Since at that time I understood that there were some breaking changes planned for version 2, I decided to wait for org-roam v2 to be released and re-evaluate the situation.
In the meantime, my Zettelkasten has continued growing. Today, it contains 1345 zettels. After org-roam v2 was released, David Wilson at System Crafters did a series of videos showing the power of org-roam. As always, David's videos are of great help to get started and he has the rare ability of guiding the interested crafter so that he or she is able to customize thing as wanted.
I therefore installed org-roam and even wrote the code to migrate my Zettelkustom to org-roam. I was an interesting exercise that allowed me increase my knowledge of Emacs Lisp and get familiar with the org-element API.
However, I am not sure that I want to do the migration. Although org-roam is very rich and has a large community of users, I have the feeling that it does to many things that I don't need. I guess that, if I was starting with org-mode, org-roam would be the good choice, but I have been using org-mode for personal organization (with GTD), note taking, writing scientific papers and reports, doing literate programming, and may more things.
And I have my personal preferences and habits that I will likely not change. For instance, for me, mixing project management and Zettelkasten does not make sense. I also don't need a special integration between Zettelkasten and my bibliographic database (org-ref and ivy-bibtex are all I need).
Therefore, by now, I'll stick to my 2 capture templates and 2 simple functions that I understand well.
I any case, all this shows the power of org-mode and its ecosystem.
Listen to a random album and generate a log entry (all with Emacs, of course)
When I was young, and vinyl records were not a cool thing but just the usual thing, I used to sit down and listen to music. Actually, I used to listen to albums, which is a forgotten concept that has been replaced by playlists. Anyway.
The fact of just listening to music and not doing anything else has been a luxury for years, but two years ago, I decided that I would sit down and listen again to music with full attention. Unfortunately, I don't have my vinyl collection anymore. All my music has been digitized and lives in the hard disk drive of my laptop. This has the great advantage of being available everywhere I go.
I of course use Emacs as my media player. And I use EMMS because it was the only solution available when I started and I like it. EMMS allows to browse the available music by album, artist, song, etc. So, when I want to listen to an album, I can just do M-x emms-browse-by-album and choose one album. This is what the buffer with the albums looks like:
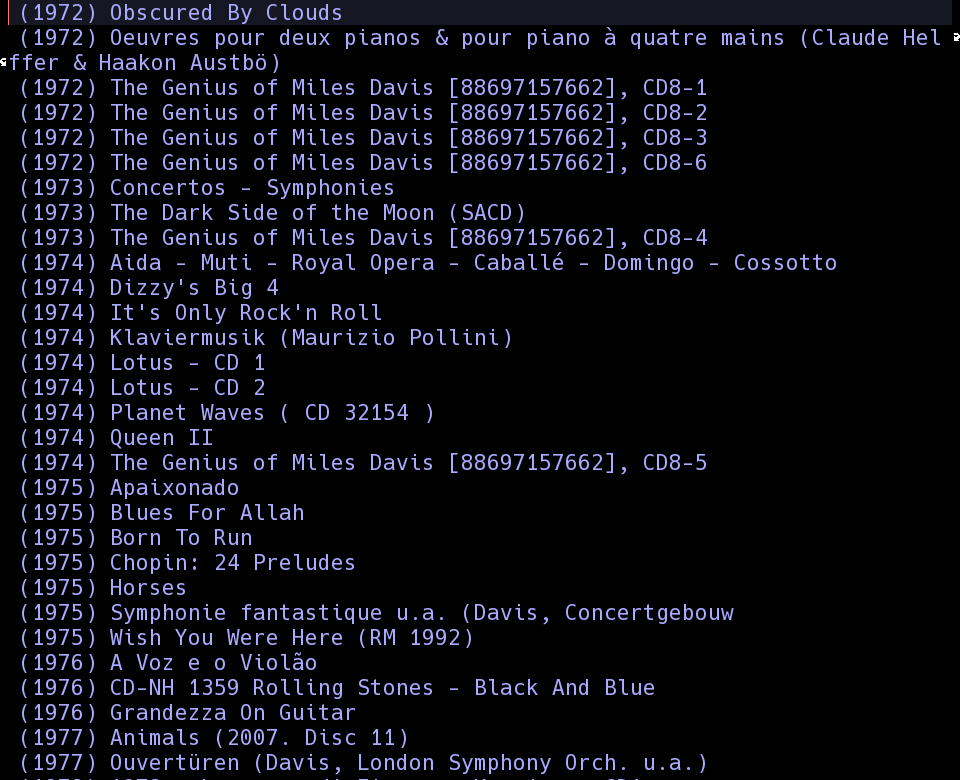
So for a couple of years I have had a weekly ritual, on Sunday afternoons, where I choose an album, put my comfortable headphones and listen to a full album, track by track, in the order they were defined by the artists. Then, I log the album to an org-mode file, so that I can keep track of what I listen.
The issue I have had is of course choosing what to listen to. One year in this new habit, I decided that I would choose the album randomly. So I started using M-: to type (random 1077)1, then M-x goto-line with the result of the random choice.
Of course, after several weeks, this became tedious and I had to automate it. I also decided that I did not want to write the log entry by hand. This is what I came up with:
(defun my/emms-play-random-album () "Play a random album from the EMMS music database. Generate an org entry with album artist and listened date for my records." (interactive) (emms-browse-by-album) (let ((nlines (count-lines (point-min) (point-max)))) (goto-line (random nlines)) (emms-browser-add-tracks-and-play)) (let* ((album (alist-get 'info-album (emms-playlist-current-selected-track))) (artist (alist-get 'info-artist (emms-playlist-current-selected-track))) (org-entry (format "* %s\n:PROPERTIES:\n:ARTIST: %s\n:LISTEN_DATE: %s\n:END:\n" album artist (format-time-string "[%Y-%m-%d %a]")))) (kill-new org-entry) (message org-entry)))
The function is easy to understand. I start by opening the album browser. Then, I count the number of lines in the buffer, and jump to a random line. The call to (emms-browser-add-tracks-and-play) just does what it says. This is just automating what I was doing by hand, but calls the same commands I was using.
I am more proud of what follows, which allows me to generate the bit of org-mode text that I need for my logs. Here, I get the name of the album and the artist of the track that just started playing using the appropriate EMMS internal function. Then I format the string with an org headline containing the album title and a property drawer with the artist and the date. It looks like this:
* Undercover :PROPERTIES: :ARTIST: Rolling Stones, The :LISTEN_DATE: [2021-09-26 Sun] :END:
I don't automatically put the entry in the log file, because sometimes I play a random album without wanting to log it. What I do here is put the entry in the kill ring so I can yank it in the appropriate place. And I also display it in the echo area.
This is yet another example of how powerful living in Emacs is. You can bridge packages that were not designed to work together (here EMMS and org-mode) to automate things. In other operating systems, if the apps are not from the same vendor and that they have not foreseen to use them together, you can't do that.
Another nice thing here is that the EMMS buffer (the album list here, but it is the same with the playlists, or any other buffer) is just text, so you can move around as in any other buffer (with goto-line in this example).
Finally, being able to use any internal function or variable of a package (emms-playlist-current-selected-track in my case) is very handy. As always, in Emacs, everything (the code, the documentation, etc.) is always available for the users to do whatever they need.
Footnotes:
yes I have that many albums
Fetch e-mail with mbsync in Emacs with a hydra to choose the channel
E-mail is my preferred way of communication, even if some say that e-mail is doomed.
I read my e-mail with Gnus in Emacs. The IMAP back-end in Gnus can sometimes be slow over the network and therefore lock Emacs while fetching. Another drawback of IMAP is the need to be on-line to access the e-mails on the server. Finally, having a local copy of all my messages is important for e-mail provider independence.
This is why I use mbsync/isync to get my e-mail for several accounts. This can happen outside of Emacs by calling the mbsync command which will use the appropriate configuration in .mbsyncrc to do its thing. I could put this on a cron job, but I prefer to run the e-mail fetching at my pace. Since my interface to the computer is Emacs, I want to be able to use mbsync from Emacs.
It shouldn't be difficult to write an Elisp function to call an external process running mbsync, but Dimitri Fontaine put together mbsync.el which does this cleanly logging output to a dedicated buffer and warning if things go wrong when trying to connect to servers.
Unfortunately, mbsync.el runs mbsync with the -a flag, which means that all channels (that is the e-mail accounts configured in .mbsyncrc) will be fetched. While this is a sane default, I sometimes want to fetch just one e-mail channel. The author of mbsync.el had the nice idea of providing a customizable variable to store the flags:
(defcustom mbsync-args '("-a") "List of options to pass to the `mbsync' command." :group 'mbsync :type '(repeat string))
We can therefore exploit this to change the flags. I wrote the following function to call mbsync for a particular channel:
(defun gd/mbsync-single-channel (channel-name) "Fetch e-mail with mbsync for a single channel" (interactive "smbsync channel: ") (message "Fetching mail for channel %s" channel-name) (let ((mbsync-args (list channel-name)) (mbsync-buffer-name (format "*mbsync %s*" channel-name))) (mbsync)))
The function takes a string containing the channel name and will use it as the flag to call mbsync. I also change the name of the the buffer where mbsync.el will write the logs (mbsync-buffer-name is a variable defined in mbsync.el). Binding the variables with let leaves them as they were before calling the function.
This function can be called as an interactive command (with M-x), but can also be used to define one function for each e-mail channel:
(defun gd/mbsync-proton () (interactive) (gd/mbsync-single-channel "proton")) (defun gd/mbsync-fastmail () (interactive) (gd/mbsync-single-channel "fastmail")) (defun gd/mbsync-gmx () (interactive) (gd/mbsync-single-channel "gmx")) (defun gd/mbsync-garjola () (interactive) (gd/mbsync-single-channel "garjola"))
I am not very happy with this approach, since there is lots of redundancy. Maybe I could use some macros to simplify this, but I am not proficient enough in Elisp yet.
With these functions, I can define a hydra which will provide a menu to select the e-mail channel to fetch.
(defhydra gd/hydra-mbsync (:timeout 4) "Fetch e-mail with mbsync" ("p" gd/mbsync-proton "proton") ("f" gd/mbsync-fastmail "fastmail") ("x" gd/mbsync-gmx "gmx") ("g" gd/mbsync-garjola "garjola")) (global-set-key (kbd "<f9> O") 'gd/hydra-mbsync/body)
Now, when I type <f9> O, the following menu appears in the mini-buffer.

And I can select which channels to fetch. Yes, channels in plural, because this is a persistent menu which stays there for 4 seconds (the timeout parameter of the hydra) and I can select several of the channels.
